
AWS-Powered MLOps Workflow
How Can AWS Enhance MLOps Workflow Efficiency?
AWS enhances MLOps workflow efficiency by offering a range of tools that automate and streamline various stages of machine learning projects. These tools facilitate easier collaboration on model development, automate the process of integrating and deploying machine learning models, and ensure efficient management of the infrastructure needed for these models.
The project focused on constructing an MLOps pipeline with AWS CodeCommit for model development collaboration, and AWS CodeBuild for CI/CD pipeline automation. It encompassed using AWS SageMaker for the training and deployment phase, Amazon S3 for data storage, and AWS CloudFormation for infrastructure setup. The deployment strategy covered environment-specific rollouts, local testing, and the use of AWS Lambda and Step Functions for automated processes, complemented by CloudWatch for monitoring and scaling in the production environment.
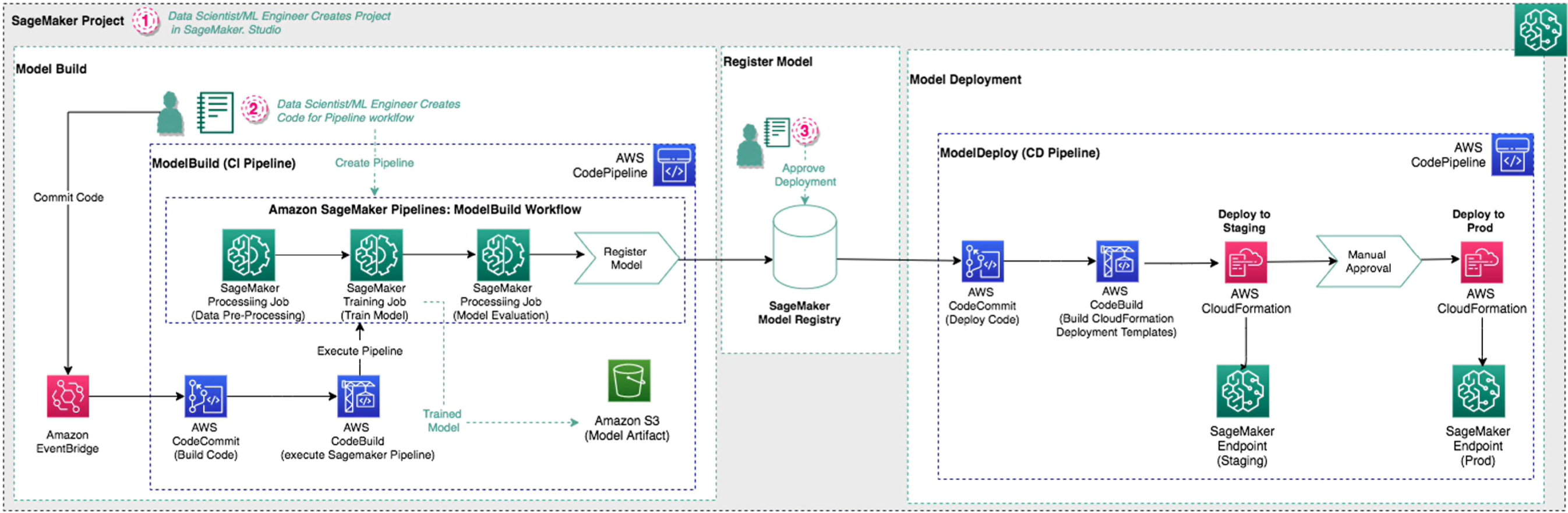
Comprehensive AWS SageMaker Pipeline Deployment
Training Pipeline
sagemaker-train-pipeline.ipynb: Building a machine learning pipeline including data preprocessing, model training with hyperparameter tuning, model evaluation, and conditional model deployment based on performance metrics.
Inference Pipeline
sagemaker-inference-pipeline.ipynb: Creating an inference pipeline and using batch transformation capabilities.
Architecture of CI/CD Pipeline
1. Repository Creation in AWS CodeCommit
- Store machine learning model source code and related files.
- Manage model training and inference images.
2. Utilizing Amazon S3:
- Store raw data for preprocessing.
- Save transformed datasets post-processing.
3. Setting Up CI/CD Pipeline Assets:
- Use AWS CodeCommit and CodeBuild for pipeline automation components.
- Test machine learning models locally to ensure functionality before deployment.
4. Infrastructure Deployment using AWS CloudFormation:
- Employ Infrastructure as Code (IaC) to deploy necessary resources for machine learning workflows.
5. Automated Model Training with AWS SageMaker:
- Facilitate automated model training processes using SageMaker.
6. Managing MLOps Pipeline Deployment:
- Deploy trained models to various environments like staging, development, or production.
- Manage the transition of models between different environments.
7. MLOps Pipeline Architecture:
- Trigger the pipeline by uploading new or updated datasets or updating source code in AWS CodeCommit.
- Implement AWS Lambda functions for initiating ETL processes and submitting AWS Glue jobs for data preprocessing and feature engineering.
- Monitor the model training process in SageMaker using AWS CloudWatch events.
- Incorporate training approval steps and conditional progression based on model training results.
- Deploy the trained model using AWS CloudFormation and create a SageMaker endpoint for model serving.
- Execute automated system tests using AWS Step Functions to evaluate model performance against predefined thresholds.
- Proceed with deployment to production, implementing autoscaling policies and data capture for quality monitoring.
- Complete the pipeline execution upon successful deployment to production.
End-to-End MLOps Pipeline Configuration on AWS
Create Data Repositories
- Creating S3 Buckets: Create one S3 bucket to store raw and pre-processed machine learning training data and another to store output of feature engineering tasks (acts as a source repository for the model training stage).
- AWS Code Commit: Repository in AWS CodeCommit to store the machine learning source code, pipeline configuration files, and other related code assets and clone this repository into the AWS Cloud9 environment for further development and tracking.
- Elastic Container Registry (ECR): Repository for storing training and inference container images.
- repository_validation.py: Script to validate the creation and configuration of these resources.
Create Pipeline Assets
ETL Job File (preprocess.py): Script to handle automation of data pre-processing and feature engineering. It includes a function to split the dataset into training, validation, and test sets and performs tasks such as one-hot encoding and data restructuring. The processed data is then uploaded to an S3 bucket.
ETL Job Configuration (etljob.json): This configuration file specifies that the job is a Python shell job, setting the Python version and the job’s purpose (featurizing the dataset).
Model Training file (model.py): Contains the training function for a deep learning neural network for regression tasks, using TensorFlow.
API and Web Server Files (app.py, wsgi.py, Nginx configuration): The app.py script sets up a Flask application to provide a prediction service API. The wsgi.py file acts as a web server gateway interface. Nginx configuration is included for setting up the web server.
Docker File: Specifies the instructions to assemble the container image, including setting up the working directory, copying necessary files, and exposing the required port.
Build Configuration (build.py): A Python script that generates CloudFormation parameters unique to both development and production environments. It selects the latest approved model package and generates the necessary parameters for deployment.
CodeBuild Specification (buildspec.yaml): Contains instructions for AWS CodeBuild to configure the CloudFormation parameters generated by build.py.
SageMaker Training Job Configuration (trainingjob.json): Specifies the configuration for the Amazon SageMaker training job, including the instance type used for training.
System Test Files: build.py constructs an automated workflow using AWS Step Functions, defining the steps involved in the system test.
buildspec.yaml contains instructions for building the system test workflow.Assets folder: Cloud formation templates detailing resources like SageMaker models and endpoints, specifying configurations for development and production environments.
- Perform unit testing
- Build the docker container
- Test the training function
- Test the prediction function
- Test the model server API
Perform system test
Pipeline Components - mlops-pipeline.yml:
Parameters: Defines customizable parameters like ImageRepoName, ImageTagName, ModelName, and RoleName. These parameters are used throughout the template to create resources with specific names and configurations.
Lambda Functions:
CreateModelGroup: A Lambda function to create a SageMaker Model Package Group for versioned, production-grade models.
TrainingLaunchJob: Starts a new SageMaker Training Job.
EtlLaunchJob: Initiates a new AWS Glue ETL Job.
TrainingJobMonitor and EtlJobMonitor: Functions to monitor the status of the SageMaker Training Job and Glue ETL Job, respectively.Lambda Permissions: TrainingJobMonitorPermissions and EtlJobMonitorPermissions: Set the necessary permissions for the Lambda functions to be invoked by CloudWatch events.
CloudWatch Events: TrainingJobMonitoringEvent and EtlJobMonitoringEvent: These rules define events that monitor the completion of the training and ETL jobs and inform the CodePipeline about their completion.
AWS CodeBuild Projects:
BuildImageProject: Builds the model training and inference container images.
BuildDeploymentProject: Builds required resource properties for deployment.
BuildWorkflowProject: Constructs the system test workflow using AWS Step Functions.AWS CodePipeline (MLOpsPipeline): Describes the stages in the machine learning operations workflow, detailing each stage’s actions, such as source retrieval, image building, ETL job execution, model training, approvals, and deployments to development and production environments.
IAM Role (MLOpsRole):
Configures an IAM role with a comprehensive policy that grants necessary permissions across various AWS services involved in the pipeline. This role is assumed by the pipeline and its components to perform required actions.Artifacts and Environment Variables:
Defines artifacts and environment variables for CodeBuild projects, tailoring them to specific tasks like image building, deployment, and workflow creation.
- Create the pipeline
- Upload local lambda resources to S3 Bucket
- upload dataset to the S3 bucket
- Create cloud formation stack